
Augmented Reality und künstliche Intelligenz
- 29. Aug. 2022
- 3 Min. Lesezeit
EmoAR ist ein Prototyp einer mobilen Anwendung, die Augmented Reality und künstliche Intelligenz miteinander verbindet. Die KI erkennt den Gesichtsausdruck eines Menschen in Echtzeit. Entsprechend dem erkannten Gesichtsausdruck überlagern virtuelle Inhalte das reale Gesicht.
Wie funktioniert es?
Der Live-Stream der AR-Kamera eines Mobilgeräts wird in ein Segmentierungstool eingegeben, das im Bild Bereiche mit einem Gesicht erkennt. Diese Bereiche werden zur Inferenz in ein KI-Modell eingespeist, d. h. es bestimmt den Gesichtsausdruck. Je nach resultierender KI-Vorhersage überlagern unterschiedliche virtuelle Inhalte das Gesicht. Diese virtuelle Überlagerung erfolgt mit AR.

Wie haben wir es implementiert?
Wir haben das Projekt in 4 Phasen unterteilt:
1Datensatzanalyse: Gute Daten sind entscheidend!
Training neuronaler Netze (KI-Modelle)
Konvertierung des besten KI-Modells
Bereitstellung in der AR-App (Gesichter erkennen, KI-Modell-Inferenz, virtuelle Inhalte mit AR überlagern)
1) Den Datensatz analysieren:
Für unseren Prototypen haben wir einen kleinen Datensatz von P.-C. Carrier und A. Courville genutzt, der kostenlos auf Kaggle erhältlich ist. Er enthält jedoch nur ca. 29.000 annotierte Bilddateien als Trainingsset und ca. 3.600 Dateien als Validierungsset.
Die Bilder bzw. Gesichtsausdrücke sind in 7 Klassen eingeteilt: Wut, Ekel, Angst, Glück, Trauer, Überraschung, neutral.
Leider gibt es einige größere Probleme mit diesem Datensatz: bspw. Wasserzeichen; leere Bilder, nutzlose Informationen/überhaupt kein Gesicht; zweideutiger Ausdruck, falsch annotierte Bilder; Bilder, die nicht das ganze Gesicht frontal zeigen; der Datensatz ist außerdem unausgeglichen usw. Diese Probleme wirken sich auf die Qualität der Vorhersagen des Gesichtsausdrucks aus. Da das KI-Modell nicht mit sauberen Informationen trainiert wird und daher nicht richtig lernen kann, wird die Performance nicht gut sein. Wir arbeiteten jedoch an dem Prototypen weiter.






2) Training verschiedener Modelle
Wir haben sowohl verschiedene vortrainierte Modelle (Transfer Learning) als auch ein eigenes Keras-Modell trainiert. Für Transfer Learning haben wir u. a. MobileNet, FaceNet, ResNet angepasst, trainiert und getestet; für das eigene Keras Modell entwarfen wir eine neuronale Netzwerkarchitektur.
In allen Fällen haben wir die klassischen Hyperparameter angepasst, Data Augmentation angewendet, verschiedene Lernraten der Optimizer ausprobiert usw.

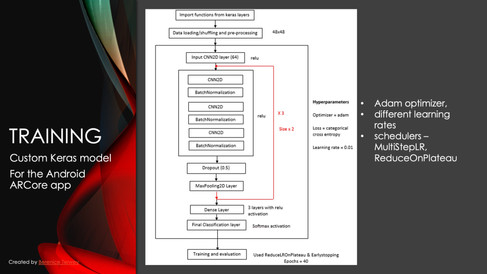


3) Konvertierung und Import des KI-Modells
Für die Nutzung in einer mobilen App konvertierten wir unser KI-Modell in ein Format, welches von der Zielplattform unterstützt wird. Zunächst ist vor der Konvertierung die Inspektion des Modells sinnvoll. Inspektionstools wie TensorBoard und Netron sind zu diesem Zweck sehr nützlich. Etwas Code ist erforderlich, um das KI-Modell zu konvertieren. Während dieses Prozesses sollten keine Informationen verloren gehen.
Wir haben zwei verschiedene Konvertierungen ausprobiert:
- Ein PyTorch-Modell, das wir über ONNX in das Tensorflow- und Protobuf-Format konvertiert haben.
- Ein Keras-Modell, das in das TensorFlow- und -.lite-Format konvertiert wurde






4) Bereitstellung für Android
Wir haben das konvertierte Keras-Modell für die Bereitstellung auf Android ausgewählt. Die wichtigsten Schritte, die wir umgesetzt haben, sind die folgenden:
Jeder Frame des Live-Kamera-Feeds wird in ein "Tiny YOLO"-Modell eingegeben, um zu erkennen, ob es überhaupt eine Person zeigt. Wir lokalisieren die Person und kopieren die entsprechenden Pixel in eine Bitmap. Danach extrahieren wir den Bereich des Gesichts und speisen das resultierende quadratische Bild des Gesichts in unser KI-Modell und seine Convolutional Neural Network-Architektur ein.
Unser KI-Modell bestimmt nun den Gesichtsausdruck, sodass wir einen Pfeil (3D-Modell) mit einer Textbeschriftung in der Textur des vorhergesagten Gesichtsausdrucks überlagern können.

Aber an welcher Koordinate sollen wir dieses 3D-Modell positionieren?
Wir berechnen die 3D-Position mit einer Projektionsmatrix, auf diese Weise erhalten wir die 3D-Koordinaten eines Punktes im 2D-Raum und umgekehrt.
Voilà, der 3D-Pfeil wird in der Nähe eines erkannten Gesichts platziert. Die Textur des Pfeils ändert sich entsprechend dem erkannten Gesichtsausdruck.
Aufgrund der oben erwähnten Probleme mit dem Datensatz stimmt mitunter die Vorhersage des KI-Modells und somit die angezeigte Pfeiltextur nicht mit dem Gesichtsausdruck, den wir selbst auf dem Bild erkennen, überein.




Nächste Schritte
Verwendung eines Datensatzes, der 3D-Meshes von Gesichtern enthält
Dies würde die Qualität des AR-Trackings sowie die Leistung des TF-AI-Modells verbessern
Definition weiterer Klassen bzgl. verschiedener Geschtsausdrücke
AR-Überlagerung virtueller Objekte auf mehrere Gesichter
Mitarbeitende: AVK Terwey; Akash Antony, IT & Data Analytics Engineer Qualcomm; Mircea Calincan, Lead ML Engineer Omdena; Mateusz Zatylny, Founder, CEO NextSynapse;
#augmented #reality #augmentedreality #deeplearning #artificialintellignece #ai #ki #künstlicheintelligenz #facetracking #facedetection #mobileapp


Kommentare